
2차 결제하기(클릭)
위의 2차 결제하기 버튼을
클릭해주세요.
2차 결제 미진행시 배송료가
추가 결제될 수 있습니다.
Best 후기홈>커뮤니티>커뮤니티>Best 후기
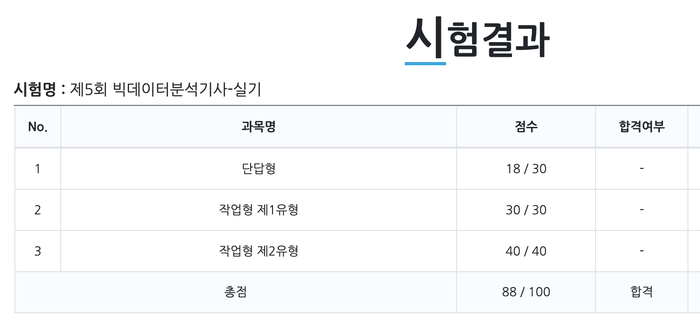
| 제목 | 빅데이터분석기사 제5회 [R] 실기 합격 후기 | 등록일 | 2023-01-16 |
|---|---|---|---|
|
R유저입니다.
1. 시험장 후기 키보드, 마우스 확인하라고 해서, 이것저것 해봤는데, 마우스 스크롤이 고장이어서, 바꿨습니다. 진동이 나도 시험 탈락이라고 다만, 이번에 규정이 바뀌어서, 본 시험만 무효이며, 다음 시험에 참가가 가능하다고 했습니다.. 기기 반드시 전부 끕시다. 중간에 누가 신분증을 지참하지 않아서 시험에 응시하지 못하고 나간사람도 있었습니다. 꼭 잘챙깁시다.
응시안내문서, 패키지 목록이 시험장에서도 열수 있게 되어있고, 응시 안내하는 문서와 패키지 목록도 띄워서 수시로 볼수가 있어서 계속 참고하면서 시험봤습니다.
f1, rmse 일단 몰라서 패스했고, 뒤의 작업형공간에서 함수를 써서 계산했습니다. 패키지목록에서 metric과 관련된 함수 MLmetrics, MedelMetrics를 찾고, ls(’package:MLmetrics’)를 써서 함수목록을 얻은 다음, 해당 함수목록에서, f1score, rmse구하는 패키지를 찾아 그냥 함수에 넣어서 답을 도출했습니다.
2.5 등 소숫점은 문자취급하지 않으므로 들어가도 되는것 같습니다.)
이것때문에 2개 더맞았습니다. 덕분에 6점 추가되었습니다.
에러가 났지만 침착하게 찾아서 잘 고쳤습니다. 하지만 파이썬과 다르게 R에서는 어디서 에러가 났는지 표시해주지 않기 때문에 천천히 잘 찾아야합니다.
막상 시험장의 시험하는곳에서는 cat()이라고 예시가 되어있어 cat을 썼습니다. print로 결과를 내어도 괜찮을 것 같습니다.
as.integer를 쓰면 벡터에 이름등등이 모두 날라가고 정수형으로 바뀌므로 정답도출시 마지막에 꼭 as.integer를 썼습니다.
그냥 랜덤포레스트, ntree = 50으로 결과가 빨리나오도록 설정했고, 돌리면 3초만에 예측치가 나왔습니다. 그대로 그냥 간단하게 제출 했습니다. 다행히 40점 만점이 나왔네요.
변수처리 등등 전처리에 절대 시간 쏟지 말고, 그냥 랜덤포레스트 돌아가는 최소한의 코드만 작성하여 간단하게 제출하고 나오는것을 추천드립니다. (랜덤포레스트는 변수변환, 더미화, 정규화등 필요하지않고, 결과의 수준도 매우 높음) (그냥 결측치만 잘 메꿔서 그냥 무조건 랜덤포레스트 돌리는것이 최고의 효율과 최고의 결과를 뽑아낼것입니다.)
2. 시험준비 작업형1 사용패키지 : tidyverse(readr, dplyr, tidyr, lubridate, stringr, purr, ...) 데이터 형식은 무조건 티블로 변환 했으며, (tibble로 바꾸면, 보기좋게 보여주므로 매우 편하고 데이터 조작시 오류도 적습니다) %>% 파이프라인으로 연결하면서 데이터를 조작했습니다. (익숙하지 않다면 반드시 익혀야합니다.)
datamanim의 작업형1 100문제를 모두 풀어봤습니다. (난이도 매우 극상이고, 뒤쪽에 시계열과 문자열, split~apply~combine이 매우 빡셉니다. 하지만 lubridate, stringr, purr 패키지를 이용하여 연습하면 자신감 급상승합니다. 시험합격을 원한다면 그냥 kaggle연습문제만 잘해도 되고, (60점 보장.) 실력의 상승을 정말 원하시면 datamanim연습문제를 열심히 하는것도 매우 좋을것 같습니다.) (완성시 100점 보장)
전처리 사용 패키지 : recipes => 모든 전처리를 해당패키지를 이용 => character형식도 자동으로 factor화 되어 유용. 분류, 회귀 패키지 : caret의 랜덤포레스트 => caret(y~x, data, method = 'rf', ntree = 50) => 킹왕짱.
(패키지 뒤져서 사용법 찾아서 적용하려함)
저도 머신러닝 해본적이 없어서 처음하는것이었기 때문에 도서을 참고하여 대략적인 흐름이나, 최소한의 구동되는 모델을 몇번 연습해보고, (이것으로만 하는것은 비추드립니다. 코드가 구리고 통일성이 없어서 오히려 혼란에 빠질수 있을 것 같습니다. 반드시 위에서 보여드린 caret의 랜덤포레스트로 모든것을 조지십시오. 분류든 회귀든 상관없이 그냥 모두 해결가능합니다.) 성능이 잘나오고 빠르게 결과가 나온다는 랜덤포레스트 기준으로 코드를 정했습니다. 그리고 kaggle의 빅데이터분석기사 놀이터에있는 연습문제에 반복적용 했습니다.
작동원리를 파악하고, 정말 언제 어디서든 사용이 가능한 코드를 정하고 계속 익숙하게하면 시험장에서도 문제가 없을 것입니다. 주의할점이 있습니다. 오히려 복잡하게 하려고 하면 할수록 구렁텅이에 빠질것이며 시험에서도 떨어질 가능성이 커집니다. 절대 어렵게 하지마시고, 구동가능한 최소한의 코드와 모델을 정해서 그것만 능숙하게 쓸수있도록 연습하십시오. 랜덤포레스트, ntree = 50 이것만 하면 됩니다.
안전벨트 두가지도 숙지하여 가십시오.
=> ls("package:패키지명") => 패키지에 담겨있는 함수들 list를 불러와줘서, 군집분석등 갑툭튀하면 사용해야함. => 혹은 f1score, rmse를 계산하라는 문제가 나왔을때 metric관련 패키지 이름을 넣어서 함수를 뒤져서 계산할수가 있음
* 사용법 모르는 함수를 쓰려고할때 => ?함수명 => 예를들면 f1score함수를 써서 계산결과를 도출하고 싶을때 사용법을 모르면 이렇게 찾아서 결과를 얻어 낼 수 있음 작업형1, 2는 정말 쉽습니다. 처음에는 어렵겠지만 연습하다보면 누구나 풀수 있을것이며 이것만 다맞아도 합격입니다. 초보라면 반드시 최소한달이상은 집중해서 연습하시고 모르는것이 있으면 데이터분석기사 단톡방에 무조건 들어가서 질문하시고, 마지막 1,2주전부터 단답형 준비하면 합격하실 수 있을 것입니다. |
|||